Kaggle Dogs-vs-Cats with Keras
This design shows how to use the Keras flow_from_directory method and the on-the-fly image augmentation to increase prediction accuracy of a simple CNN when applied to Kaggle's dogs-vs-cats database of images.
Introduction
The Github repository should be downloaded or cloned as preferred. The repository contains the following python scripts:
- create_datasets.py - unzips the Kaggle dogs-vs-cats dataset and moves images into class folders.
- train.py - runs all training, evaluation and prediction accuracy testing of the CNN.
- customCNN.py - the definition of the CNN to be trained..
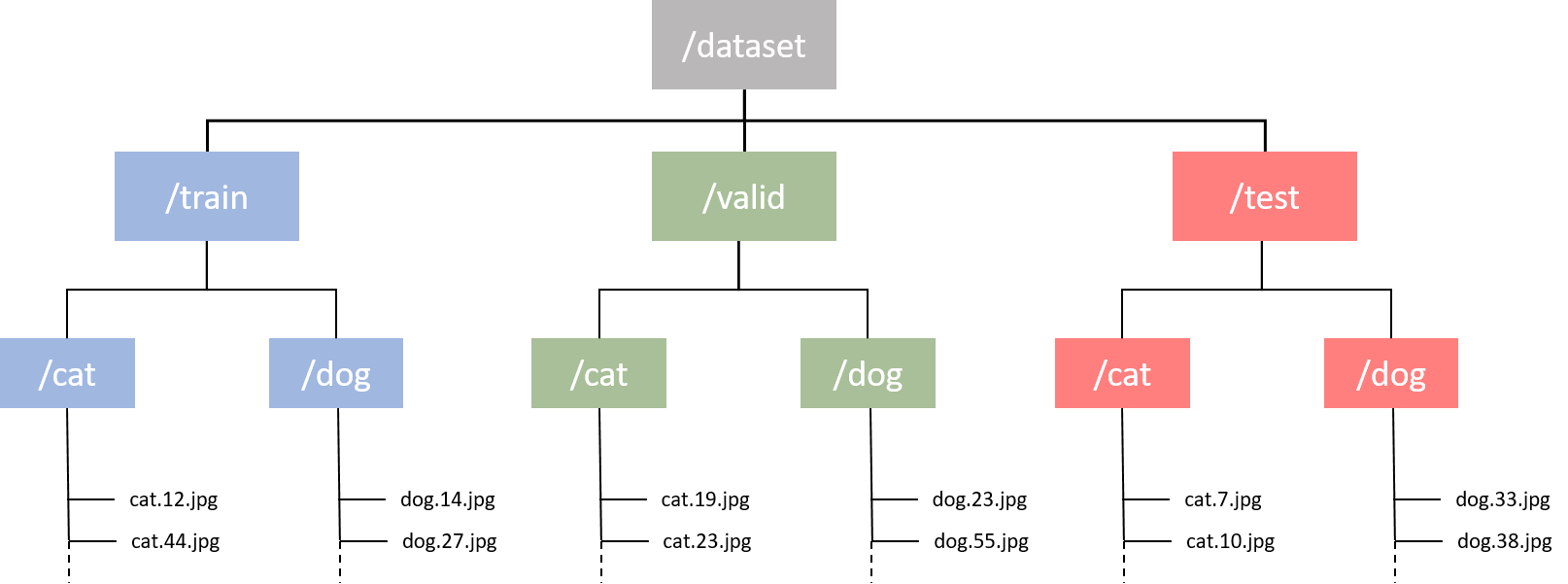
Dataset preparation
Once the Github repository has been download or cloned, the
Kaggle dogs-vs-cats dataset should be downloaded (Note that this requires a login for the Kaggle website).
The downloaded zip archive should be placed in the same folder as the python scripts from the GitHub repo.
Run the create_datasets.py script and this will unzip the dataset and move the images to a directory structure that matches the requirements of the Keras
.flow_from_directory() method. The images are shuffled before being assigned to class folders.
The Convolution Neural Network
The customCNN.py script uses the Keras Functional API to describe the simple CNN. The CNN is fully-convolutional - the dense or fully-connected layers have been replaced with convolutional layers that have their kernel sizes, number of filters and stride lengths set such that they create output shapes that mimic the output shapes of dense/FC layers. There are no pooling layers - these have also been replaced with convolutional layers that have their kernel size and strides set to the same value which is > 1. The output activation layer is a sigmoid function as we only have two classes - if the output of the sigmoid is > 0.5, the predicted class is 'dog', less that 0.5 is a prediction of 'cat'. The CNN has deliberately been kept simple (it only has 8 convolutional layers) so the expected prediction accuracy will not be higher than approximately 90%. To reduce overfitting, batch normalization layers have been used and also L2 kernel regularization.

Training features
The train.py script executes the training, evaluation and prediction accuracy testing and uses some advanced features of Keras:
- Images are read from disk using the flow_from_directory() method.
- On-the-fly image augmentation is used:
- Normalization of pixel values from 0:255 to 0:1
- Images are resized to 200(Height) x 250(Width) using bilinear interpolation.
- Random flipping along the vertical axis.
- Random vertical and horizontal shifts.
- Shuffling of the images between epochs.
- Early stopping of training if the validation accuracy stops increasing for a certain number of epochs.
- The CNN parameters from the epoch with the best validation accuracy are automatically restored after training stops.
- Saving of the trained model as JSON and HDF5 file.
- Prediction results saved to a .csv file using Pandas.
The python code and Jupyter notebooks are available on my Github page.
If you have any questions or comments about this design, please email me at designs@markharvey.info